
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- SECGAME
- pwnable
- SQLi
- web
- blind-sqli
- cryptohack.org
- 예전글 #CNN
- pwn
- blind_sqli
- XSS
- regex
- PS
- JS
- 예전글
- cookie
- 예전글 #PS
- Bob
- cce2023
- Crypto
- webhacking.kr
- Pwnable.kr
- 백준
- pwn.college
- HTB
- Today
- Total
아모에요
합성곱 신경망(CNN) 본문
합성곱 신경망은 지금까지의 신경망과는 약간 다른 구조를 갖는다.
일반적인 신경망은 인접하는 모든 계층과 연결된 구조를 갖는데, 이를 완전연결이라 하며 완전연결된 계층을 Affine계층이라고 한다. 예를 들어서 층이 4개인 완전연결 신경망은 다음과 같이 나타난다.

각 층마다 Affine계층과 ReLU 활성함수가 존재해서 데이터를 처리하고, 마지막 층에서는 Softmax함수로 최종결과를 출력한다.
반면 CNN은 Conv계층(합성곱 계층) 과 Pooling계층(통합 계층)이 나타난다.

각 층마다 Conv계층과 ReLU 활성함수가 연속으로 존재하며, 뒤에 Pooling 계층이 존재할수도 하지 않을수도 있다. 출력층과 가까운 층에서는 Affine-ReLU의 조합을 사용하기도 한다. 마지막 출력층에서는 Affine-Softmax의 조합을 사용해서 결과값을 출력한다.
기존 Multi-Layer Neural Network(MLNN)은 다양한 문제가 존재하였다. 이미지같은 행렬로 주어지는 데이터의 경우 16 x 16px의 작은 크기의 영어 글자를 입력받는다 하여도 256개의 변수가 각 이미지마다 주어지며 이를 100개의 뉴런으로 입력받는경우 256 x 100 + 100 * 26개의 가중치가, 100 + 26개의 편향값이 정해져야 한다. 층이 많아질 경우 이는 기하급수적으로 늘어날 것이며 컴퓨터의 성능이 아무리 좋아도 이들을 모두 계산하는 것은 무리일 것이다. 또한 글자를 2픽셀씩만 오른쪽으로 밀기만 하더라도 데이터가 완전히 달라져서 계산을 새로이 해야 하며, 글자가 커지거나 회전되거나 변형되면 이에 대한 학습 데이터를 충분히 넣어주어야 하므로 많은 양의 데이터가 필요하다는 문제점이 존재한다. 결국 많은 양의 가중치와 편향값, 데이터에 의해 총 학습시간이 증가하는 문제에 도달하게 된다.
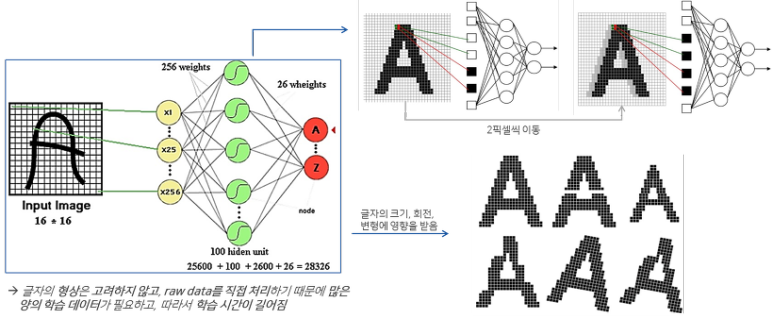
이를 극복해 내기 위해 생겨난 것이 합성곱 계층이다. 위에서 데이터를 1차원의 배열로 처리했다면, CNN에서는 2차원의 형태를 유지한 채 데이터의 크기만 축소하는 식으로 2차원 데이터를 처리하는 방식을 사용하게 된다.
합성곱 계층의 연산 방식은 다음과 같다. 먼저 Padding이 존재해 데이터의 주변을 특정한 값으로 채우게 된다. 이는 가장자리의 데이터가 가지는 특징이 합성곱 계층의 연산에서 사라지는 문제가 발생하기 때문이다. 또한 출력 데이터의 크기를 조정하는데에 사용한다. 주로 Padding의 모든 값이 0인 zero-padding을 사용하게 된다.

또한 Stride의 값이 존재하는데 Padding이 추가된 데이터 위를 필터가 움직이게 되는데, 이때 움직이는 간격을 의미한다. 예를 들어 Stride 값이 1이면 한칸씩 필터가 이동하면서 계산이 일어나게 된다. Stride 값이 1일 경우 출력데이터의 크기는 Pooling 계층에서만 조절하게 할 수 있다.

이제 필터를 적용하는 방법에 대해서 알아보자. 위의 예시에서 3 x 3 필터를 적용하였을 때 결과값은 다음과 같다.

처음부터 5번만 계산하였는데 9번의 계산을 통해서 3x3 행렬을 결과값으로 얻을 수 있다.
풀링 계층은 합성곱 계층과 비슷한 역할을 하나 주로 데이터의 크기를 축소하는 데에 사용한다. 주로 합성곱 계층에서는 데이터의 크기를 유지하며, 풀링 계층에서 데이터의 크기를 축소해 내 특징적인 부분을 잡아내는데에 중점을 둔다. 풀링에는 Max-pooling과 Average-pooling이 있는데 Max-pooling은 영역에서 최대값을, Average-pooling은 평균값을 계산해 내는 방식이다.풀링 계층에서는 풀링의 영역 크기와 Stride 값을 같은 값으로 둔다.
예를 들어서 4 x 4 행렬에 대해서 2 x 2 맥스 풀링 (Stride 값을 2로 둔다)를 시행하면 다음과 같이 나타난다.

이렇게 CNN에 대해서 알아보았다.
